Dissertation Topic #1: Generative Engine Optimization (GEO) – The "Death of SEO"
To study the future of AI, you must look to the past of psychology. This blueprint for an empirical dissertation on Generative Engine Optimization (GEO) shows how to anchor modern tech in established theory and design a rigorous experiment for a distinction grade.
Series: The 2026 Topic Blueprint Constraint: University of Bristol MSc Marketing Handbook, Empirical Dissertation
Pre-requisite Reading: The Anatomy of a Dissertation
If you are looking for a dissertation topic in 2026, please think carefully about an area of genuine interest to you but also one that serves its purpose. It is a vital part of your degree programme.
To get a Distinction, you need a topic that is novel (new tech) but anchored (old theory). A big shift in marketing right now is the move from Search Engines (Google) to Answer Engines (ChatGPT, Perplexity, Claude). Consumers are no longer searching for links; they are asking for answers. This creates a new field: Generative Engine Optimization (GEO).
Below is the Project Plan and the Execution Guide to help you execute it safely. I am basing this plan on Bristol University’s Business School dissertation guide of approximately 11,ooo words for their MSc in Marketing,
In our previous article, we established the Anatomy of a dissertation. Now, we are going to apply that structure to a real-world example.
To make this realistic, we are not operating in a vacuum. We are going to treat this as as simulation, as if you were submitting a proposal under the strict constraints of the University of Bristol MSc Marketing Handbook.
- Word Count: 10,000–12,000 words.
- Methodology: Quantitative (Survey).
- Target Grade: Distinction (70%+).
The topic is Generative Engine Optimization (GEO)—the shift from "Searching Google" to "Asking AI."
Part 1: The Title Strategy
Most students start with a topic that is too broad. They want to study "The Future of AI." The Bristol Handbook explicitly warns against this, stating that a Distinction requires a "Well argued, imaginative choice of problem area"
If you choose a broad topic, your data will be messy. If you ask 100 people "Do you trust AI?", half will imagine a Chatbot, and half will imagine a Terminator.

Many students provide title that are too vague, such as, “A study into consumer trust in Artificial Intelligence.” Trust depends on risk. You might trust AI to recommend a pizza (Low Risk), but not a mortgage (High Risk). Without defining the context, you cannot measure the variable. You need to narrow the scope to a High-Involvement sector where trust is actually the deciding factor such as high-end consumer electronics (Laptops, Phones, Cameras).
Why? It is expensive (High Risk), relies on specifications (Data-Heavy), and is a sector where "Expert Reviews" (Citations) traditionally matter. If you buy the wrong £2,000 MacBook because an AI halluncinated, that hurts.
The Approved Working Title:
"From Search to Chat: A comparative analysis of consumer trust in AI-generated product recommendations vs. traditional SERP listings in the UK High-End Consumer Electronics sector."
Choosing Your Sector
While we are using Consumer Electronics for this blueprint (because it is universally understood), you can adapt this plan to other sectors.
If you are a dual-honours student (e.g., Finance & Marketing) or have access to a B2B network, you might want to switch the sector to increase the difficulty—and potential reward.
| Sector | Diff. | Pot. | The "Trap" |
|---|---|---|---|
|
Consumer Electronics (Laptops/ Phones) |
Easy | High |
Easy to visualise. Easy to find respondents. The Safe Bet. |
|
Financial Services (Mortgages/ Investing) |
Medium | Very High | High trust barrier. Proving AI works here is a massive finding. Great for Finance majors. |
|
B2B SaaS (Enterprise Software) |
Hard | Very High | Hard to recruit. Requires access to a professional network (e.g., LinkedIn). |
Part 2: The Objectives (The Steps)
Now that we have a Title, we need a Plan. In the Bristol Handbook, the first criteria for a Distinction is a "Clear statement of purpose and research outcomes."
A common mistake is confusing the Research Question (RQ) with the Objectives. The RQ is the destination (What is the answer?). The Objectives are the stepping stones to get there.

The Central Research Question (RQ):
To what extent does the presence of 'Source Citations' in AI-generated responses influence consumer trust compared to traditional SERP listings for high-involvement purchases?
The Research Objectives:
- To Critically Review the literature on Source Credibility Theory (Hovland) and Technology Acceptance (Davis) to identify the drivers of trust in algorithmic advice. (Think? The Literature Review)
- To Measure the difference in "Perceived Credibility" between traditional Search Engines (Google) and Generative AI (ChatGPT) for high-value consumer electronics. (Think? The Experiment)
- To Analyse whether the inclusion of hyperlinked citations moderates the relationship between AI usage and Purchase Intention. (Think? The Analysis)
- To Provide strategic recommendations for electronic retailers on optimizing content for the emerging "Answer Engine" ecosystem. (Think? The Implications)
Bloom’s Taxonomy Notice the bold verbs above in the Research Objectives: Review, Measure, Analyse, Provide. These map directly to Bloom’s Taxonomy of higher-order thinking. Objectives 1 & 2 cover "Knowledge & Application." Objectives 3 & 4 cover "Analysis & Synthesis." This signals to the marker that you are not just describing a phenomenon; you are deconstructing it.
Part 3: The Literature Review (The "Smart" Shortcut)
The Problem: It is a 75-year-old book. It is likely in very limited supply, an inter library loan or behind a paywall you can't access. Trying to find it is a waste of your limited time.
Instead of hunting for Hovland, use a tool like Connected Papers to find a "Review Paper" that summarises the history for you. Consider the 'derivative works of older papers to find more recent, accessible gems.
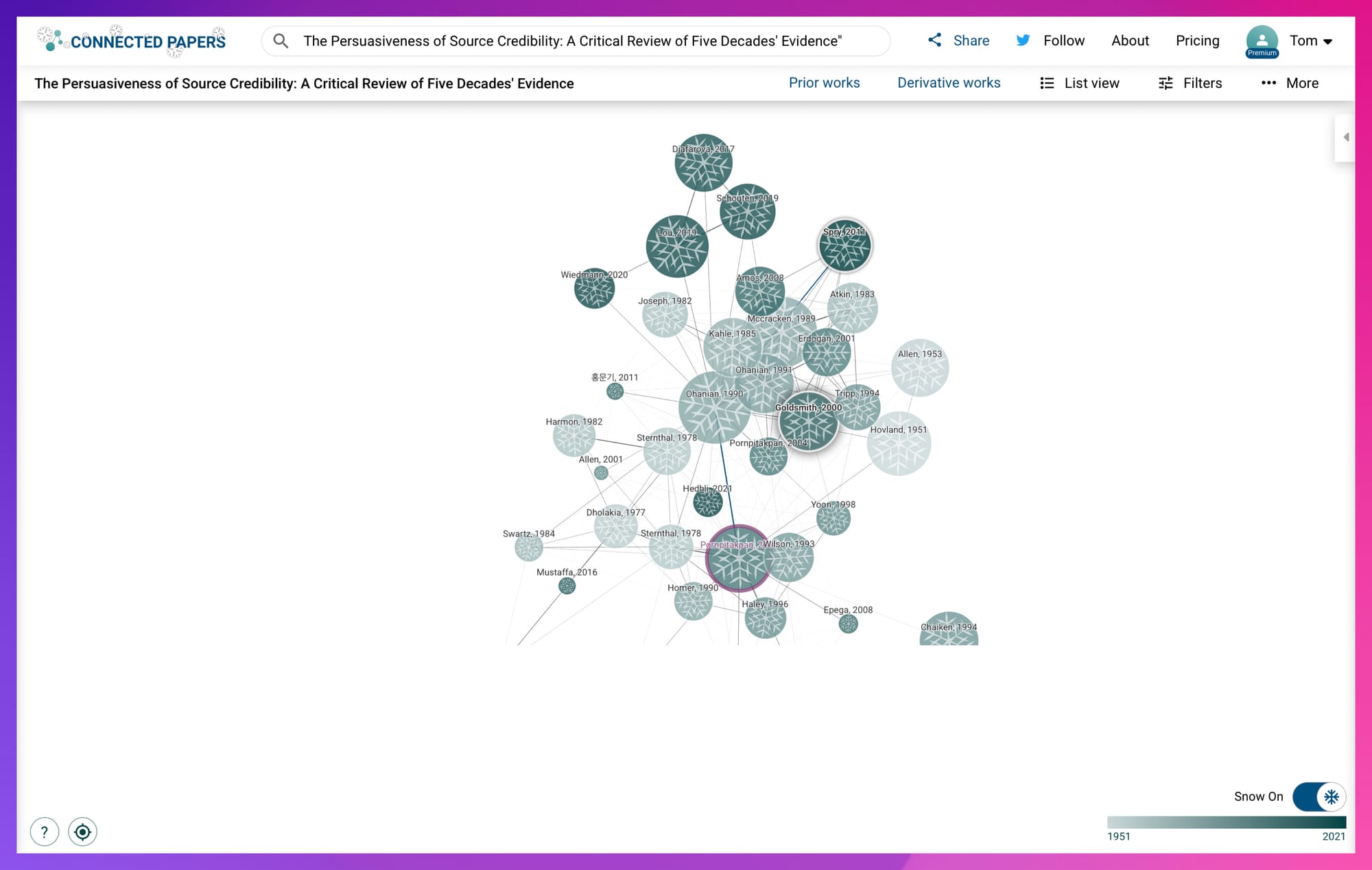
If you look at the graph above, you will see one paper acting as a massive "Hub" for this topic:
Pornpitakpan, C. (2004) 'The persuasiveness of source credibility: A critical review of five decades' evidence', Journal of Applied Social Psychology, 34(2), pp. 243–281.
This reviews 50 years of evidence. Instead of you reading 50 papers from the 1960s, you read this one paper.
- The Quote you need: The abstract confirms: "The main effect studies of source credibility on persuasion seem to indicate the superiority of a high-credibility source over a low-credibility one."
- Your Argument: "Pornpitakpan (2004) confirms that high credibility sources are more persuasive. This dissertation tests if an AI with citations is perceived as 'High Credibility'."
How to Cite "The Missing Book" (Secondary Referencing)
Since you haven't read the physical 1953 book, you cannot cite it directly in your bibliography. You must use Secondary Referencing. This is perfectly academic, perfectly honest, and saves you 10 hours of library hunting.
In your Reference List, you list:
Pornpitakpan, C. (2004)... (You do not list Hovland).
In your text, you write:
"According to Hovland (1953), cited by Pornpitakpan (2004), credibility is defined by..."
The "Dinner Party" Guest List
Now that you have your "Hub," your guest list for the Literature Review is simple; you need to make these authors "talk" to each other.
1. The Foundation (The Guide): Pornpitakpan (2004) Summarizes Hovland's theory: Humans need "Source Credibility" (Expertise + Trustworthiness) to believe information.
2. The Challenger (The Skeptic): Davis (1989) Creator of the Technology Acceptance Model (TAM). He argues that users don't care about "Credibility"; they care about Perceived Utility (Is it useful?) and Ease of Use (Is it easy?).
The Conflict: Davis would argue: "Hovland is wrong. Consumers are lazy. ChatGPT is faster than Google. Therefore, they will use it regardless of the missing citations."

3. The Bridge (The Modern Context): Sundar (2008) Argues that in digital spaces, we use "Heuristics" (shortcuts). If a website looks professional, we trust it, even if the content is AI.
4. The Tool (The Methodology): Ohanian (1990) Construction and validation of a scale to measure celebrity endorsers.
Why this one? You need a "Scale" (a set of questions) to ask your survey respondents. Ohanian created the gold standard for measuring trust. You will simply adapt it from "Celebrity" to "AI."
The Ohanian "Cheat Sheet"
Here is exactly what you need to extract from Ohanian (1990) for the GEO project. You should use the first two dimensions (Trustworthiness and Expertise) and ignore "Attractiveness" (unless the AI has a face).
Instructions to Participants: "Please rate the AI response you just saw on the following scales:"
Dimension 1: Trustworthiness
- Undependable <__ __ __ __ __ __ __> Dependable
- Dishonest <__ __ __ __ __ __ __> Honest
- Unreliable <__ __ __ __ __ __ __> Reliable
- Insincere <__ __ __ __ __ __ __> Sincere
- Untrustworthy <__ __ __ __ __ __ __> Trustworthy
Dimension 2: Expertise
- Not an expert <__ __ __ __ __ __ __> Expert
- Inexperienced <__ __ __ __ __ __ __> Experienced
- Unknowledgeable <__ __ __ __ __ __ __> Knowledgeable
- Unqualified <__ __ __ __ __ __ __> Qualified
- Unskilled <__ __ __ __ __ __ __> Skilled
Note: In the original paper, Ohanian validates these specific word pairs. By using these exact words, you can claim "Construct Validity" in your methodology chapter).
The "Numbers" Game
Finally, let's address the question every student asks: "How many references do I need?"
Many students think a literature review means "Read a lot of papers." Wrong. A Literature Review is not a list; it is an argument. The "Pass" Student cites 50 papers, but just lists them chronologically. ("Smith said this. Jones said this."). The "Distinction" Student cites 25–30 high-quality papers, but organises them by Theme (The "Turley" Method). see Turley & Milliman (2000)
For a University of Bristol, MSc Marketing Dissertation (12,000 words), aim for 30–40 references in your Literature Review chapter. But remember: Relevance > Volume. It is better to have Pornpitakpan (2004) and explain it well, than to have 10 random blog posts about AI that you barely read.
Part 4: The Methodology (The Experiment)
This is the section where the grade is often decided. The Bristol Handbook rewards "Fully justified choice of research methods" and penalises "Descriptive or anecdotal" analysis. Most students choose the "Path of Least Resistance": Recall Surveys, such as “Think back to the last time you used ChatGPT. Did you trust it?”
This is not the way to go if you want the best marks. Participants cannot accurately remember their specific psychological state from weeks ago and so it introduces memory bias. One participant remembers asking for a poem (Low Risk), another remembers asking for medical advice (High Risk). You are comparing incomparable data points and so the context of the study collapses.
A better approach would be to run and experiment with simulated stimuli. Instead of asking about the past, create a controlled scenario in the present using an Experimental Design (Between-Groups).
The Experimental Setup
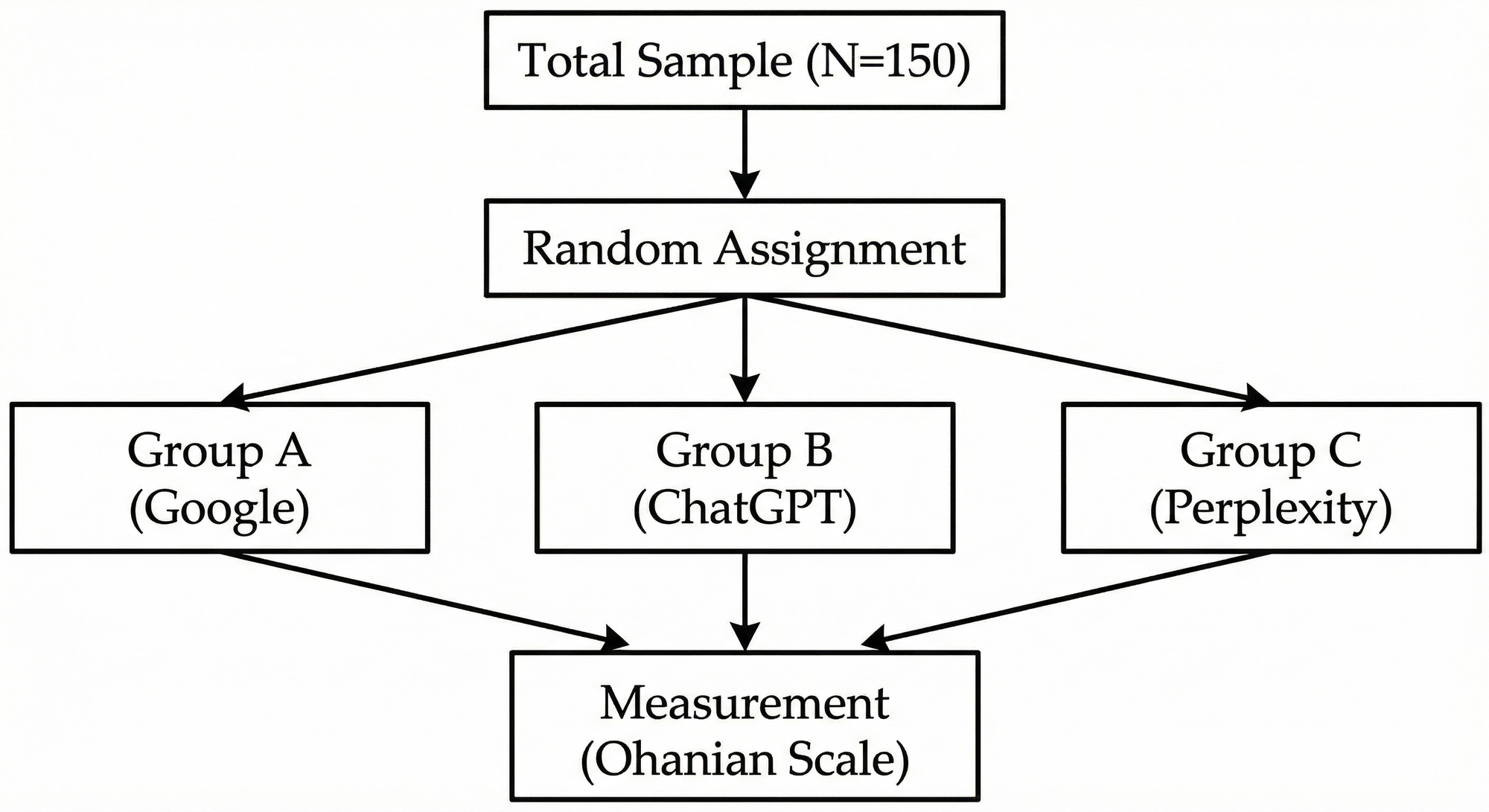
Recruit approx 150 participants (aiming for the Bristol quantitative guide of 100–200) and randomly assign them to one of three groups (A, B & C).
The Stimulus: Every participant is told: “Imagine you are looking to buy a high-end laptop for graphic design (Price: £2,000+).”
- Group A (Control): Sees a static screenshot of a Google Search Page (Traditional 10 Blue Links).
- Group B (Treatment 1): Sees a ChatGPT response (Text answer, no citations).
- Group C (Treatment 2): Sees a Perplexity.ai response (Text answer, with hyperlinked citations).
The Measurement (Applying Ohanian, 1990)
We do not ask “Did you like it?”. We use the Ohanian (1990) Scale identified in the Literature Review to measure the dependent variable: Perceived Trustworthiness.
Participants rate the screenshot on a 1–7 Semantic Differential Scale:
- Undependable — Dependable
- Dishonest — Honest
- Unreliable — Reliable
This provides a numerical "Trust Score" (e.g., 4.2/7) that can be statistically compared between groups.
Tutor’s Advisory: Execution & Ethics
Because you are showing images to humans and recording their reactions, this constitutes Primary Data Collection.
- The Handbook Rule: You must complete the Ethics Approval Form before collecting a single response.
- The Consent: You must provide a "Participant Information Sheet" that explicitly states their right to withdraw.
- The Risk: If you collect data before ethical sign-off, the dissertation is capped at a Fail.
Sample Size Strategy: The Bristol Handbook suggests a sample of 100–200 for quantitative surveys. To run a valid ANOVA (comparing 3 groups), you need approximately 40–50 people per group. Aim for 150 total responses. This provides a safety buffer for incomplete data while remaining manageable within the project timeline.
The Manipulation Check: To ensure rigour, add one binary question at the end of the survey. “Did the image you just viewed contain clickable links?” (Yes/No). It's a control question. If a participant in Group C (which had citations) answers "No", then they were not paying attention. You must exclude their data. This step demonstrates to the marker that you are controlling for attention span, a common issue in online surveys. Take this into account in terms of sample size, you will need more respondents than you use once cleaning is done.
Part 5: The Analysis & Implications
Once the data is collected, the analysis is straightforward because the design is structured.
The Statistical Test: You are comparing the Mean Trust Score across three distinct groups. The Test: One-Way ANOVA (Analysis of Variance).
The Hypothesis:
- H1: There is a significant difference in trust scores between Search (Group A) and Chat (Group B).
- H2: The presence of citations (Group C) significantly increases trust scores compared to non-cited AI (Group B).
The Discussion (The "So What?"): If H2 is supported, the implication is commercially significant. It suggests that for High-Involvement Goods (like laptops), AI is only a viable marketing channel if it provides sources. Managerial Advice: Brands should shift budget from "Keywords" (ranking for text) to "Digital PR" (getting cited in trusted publications that AI references).
Summary Checklist
| Section | Distinction Check |
| Title | Does it define the sector (e.g., Electronics) to control for Risk? |
| Lit Review | Have you used Pornpitakpan (2004) to navigate the historical theory? |
| Method | Are you using Simulated Stimuli (Screenshots) rather than recall? |
| Scale | Are you using Ohanian (1990) to ensure construct validity? |
| Analysis | Do you plan to use an ANOVA to compare the three groups? |
References & Further Reading
- Davis, F. D. (1989) 'Perceived usefulness, perceived ease of use, and user acceptance of information technology', MIS Quarterly, 13(3), pp. 319–340.
- Hovland, C. I., Janis, I. L., & Kelley, H. H. (1953) Communication and persuasion.
- Ohanian, R. (1990) 'Construction and validation of a scale to measure celebrity endorsers’ perceived expertise, trustworthiness, and attractiveness', Journal of Advertising, 19(3), pp. 39–52.
- Pornpitakpan, C. (2004) 'The persuasiveness of source credibility: A critical review of five decades' evidence', Journal of Applied Social Psychology, 34(2), pp. 243–281.
- Sundar, S. S. (2008) 'The MAIN model: A heuristic approach to understanding technology effects on credibility', in Metzger, M. J. and Flanagin, A. J. (eds.) Digital Media, Youth, and Credibility. Cambridge, MA: The MIT Press, pp. 73–100.
- Turley, L.W.M., Ronald. E. (2000) Atmospheric Effects on Shopping Behaviour: A Review of the Experimental Evidence. Journal of Business Research, 49, 193 - 211.
Was this helpful?
Join our newsletter
We share our insights on Marketing, Education, and anything else that takes our fancy. No spam. Unsubscribe anytime.
No spam. Unsubscribe anytime.



